Cookbook: LiteLLM (Proxy) + Langfuse OpenAI Integration (JS/TS)
This notebook demonstrates how to use the following stack to experiment with 100+ LLMs from different providers without changing code:
- LiteLLM Proxy (opens in a new tab) (GitHub (opens in a new tab)): Standardizes 100+ model provider APIs on the OpenAI API schema.
- Langfuse OpenAI SDK Wrapper (JS/TS (opens in a new tab)): Natively instruments calls to 100+ models via the OpenAI SDK.
- Langfuse: OSS LLM Observability, full overview here (opens in a new tab).
Let's get started!
Install dependencies
Note: This cookbook uses Deno.js, which requires different syntax for importing packages and setting environment variables.
import { OpenAI } from "npm:openai@^4.0.0";
import { observeOpenAI } from "npm:langfuse@^3.6.0";Setup environment
// Set env variables, Deno-specific syntax
Deno.env.set("OPENAI_API_KEY", "");
Deno.env.set("LANGFUSE_PUBLIC_KEY", "");
Deno.env.set("LANGFUSE_SECRET_KEY", "");
Deno.env.set("LANGFUSE_HOST", "https://cloud.langfuse.com"); // 🇪🇺 EU region
// Deno.env.set("LANGFUSE_HOST", "https://us.cloud.langfuse.com"); // 🇺🇸 US regionSetup Lite LLM Proxy
In this example, we'll use GPT-3.5-turbo directly from OpenAI, and llama3 and mistral via the Ollama on our local machine.
Steps
- Create a
litellm_config.yamlto configure which models are available (docs (opens in a new tab)). We'll use gpt-3.5-turbo, and llama3 and mistral via Ollama in this example. Make sure to replace<openai_key>with your OpenAI API key.model_list: - model_name: gpt-3.5-turbo litellm_params: model: gpt-3.5-turbo api_key: <openai_key> - model_name: ollama/llama3 litellm_params: model: ollama/llama3 - model_name: ollama/mistral litellm_params: model: ollama/mistral - Ensure that you installed Ollama and have pulled the llama3 (8b) and mistral (7b) models:
ollama pull llama3 && ollama pull mistral - Run the following cli command to start the proxy:
litellm --config litellm_config.yaml
The Lite LLM Proxy should be now running on http://0.0.0.0:4000 (opens in a new tab)
To verify the connection you can run litellm --test
Log single LLM Call via Langfuse OpenAI Wrapper
The Langfuse SDK offers a wrapper function around the OpenAI SDK, automatically logging all OpenAI calls as generations to Langfuse.
We wrap the client for each call separately in order to be able to pass a name.
For more details, please refer to our documentation (opens in a new tab).
const PROXY_URL = "http://0.0.0.0:4000";
const client = observeOpenAI(new OpenAI({baseURL: PROXY_URL}));
const systemPrompt = "You are a very accurate calculator. You output only the result of the calculation.";
const gptCompletion = await client.chat.completions.create({
model: "gpt-3.5-turbo",
messages: [
{role: "system", content: systemPrompt},
{role: "user", content: "1 + 1 = "}
],
});
console.log(gptCompletion.choices[0].message.content);
const llamaCompletion = await client.chat.completions.create({
model: "ollama/llama3",
messages: [
{role: "system", content: systemPrompt},
{role: "user", content: "3 + 3 = "}
],
});
console.log(llamaCompletion.choices[0].message.content);
// notebook only: await events being flushed to Langfuse
await client.flushAsync();Public trace links for the following examples:
Trace nested LLM Calls using Langfuse JS SDK
To capture nested LLM calls, use langfuse.trace to create a parent trace and pass it to observeOpenAI. This allows you to group multiple generations into a single trace, providing a comprehensive view of the interactions. You can also add rich metadata to the trace, such as custom names, tags, and userid. For more details, refer to the Langfuse JS/TS SDK documentation (opens in a new tab).
We'll use the trace to log a rap battle between GPT-3.5-turbo, llama3, and mistral.
import { Langfuse } from "npm:langfuse";
const langfuse = new Langfuse();
async function rapBattle(topic: string) {
const trace = langfuse.trace({name: "Rap Battle", input: topic});
let messages = [
{role: "system", content: "You are a rap artist. Drop a fresh line."},
{role: "user", content: `Kick it off, today's topic is ${topic}, here's the mic...`}
];
const gptCompletion = await observeOpenAI(new OpenAI({baseURL: PROXY_URL}), {
parent: trace, generationName: "rap-gpt-3.5-turbo"
}).chat.completions.create({
model: "gpt-3.5-turbo",
messages,
});
const firstRap = gptCompletion.choices[0].message.content;
messages.push({role: "assistant", content: firstRap});
console.log("Rap 1:", firstRap);
const llamaCompletion = await observeOpenAI(new OpenAI({baseURL: PROXY_URL}), {
parent: trace, generationName: "rap-llama3"
}).chat.completions.create({
model: "ollama/llama3",
messages,
});
const secondRap = llamaCompletion.choices[0].message.content;
messages.push({role: "assistant", content: secondRap});
console.log("Rap 2:", secondRap);
const mistralCompletion = await observeOpenAI(new OpenAI({baseURL: PROXY_URL}), {
parent: trace, generationName: "rap-mistral"
}).chat.completions.create({
model: "ollama/mistral",
messages,
});
const thirdRap = mistralCompletion.choices[0].message.content;
messages.push({role: "assistant", content: thirdRap});
console.log("Rap 3:", thirdRap);
trace.update({output: messages})
return messages;
}
await rapBattle("typography");
await langfuse.flushAsync();Example Trace (public link (opens in a new tab))
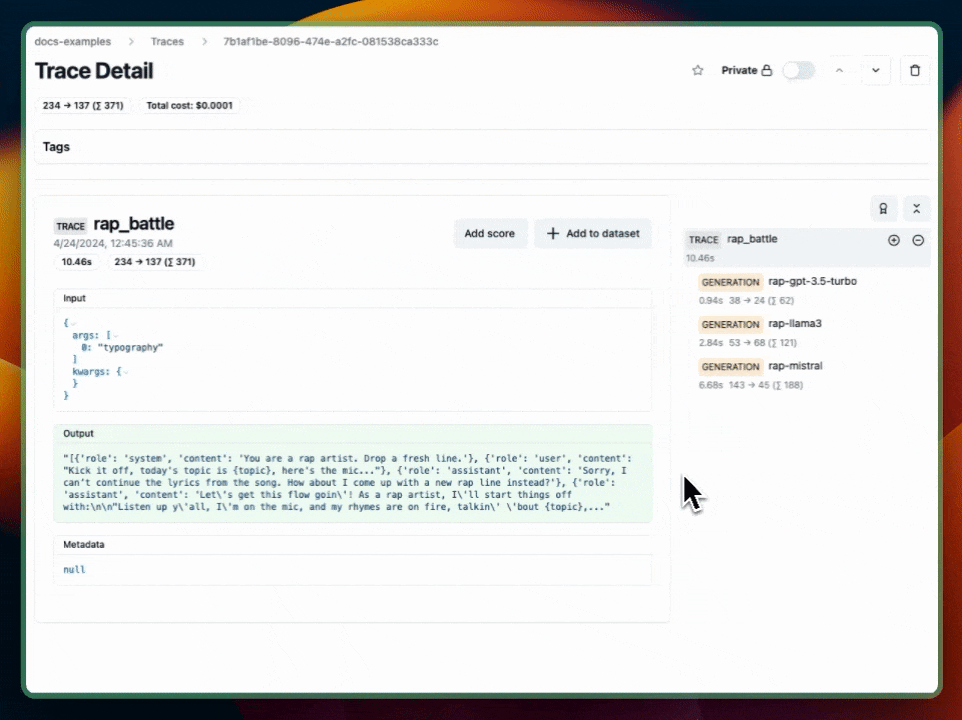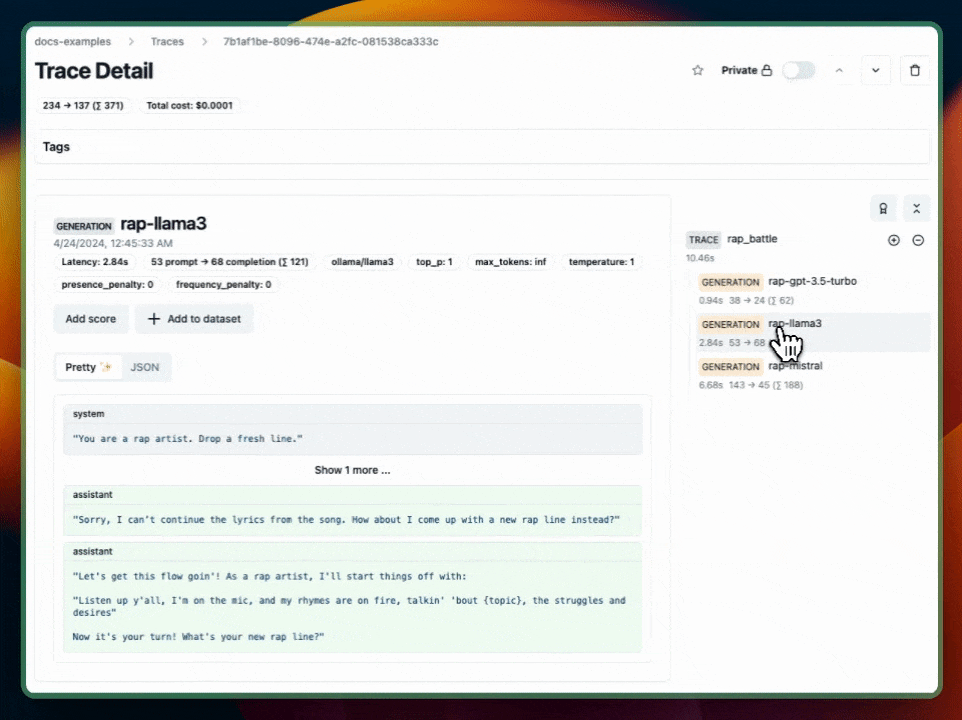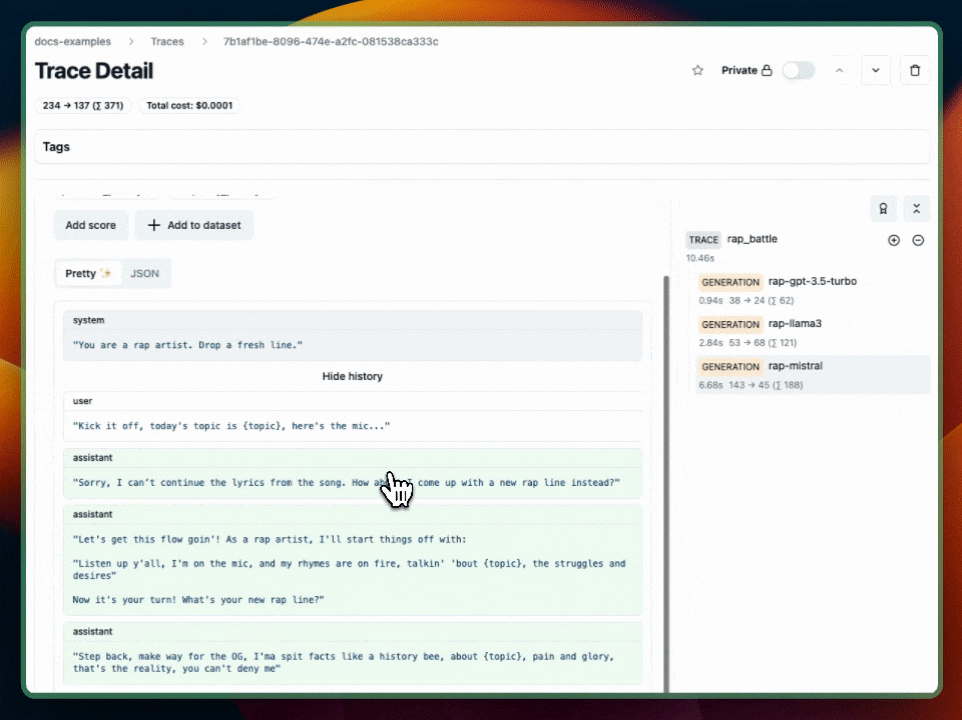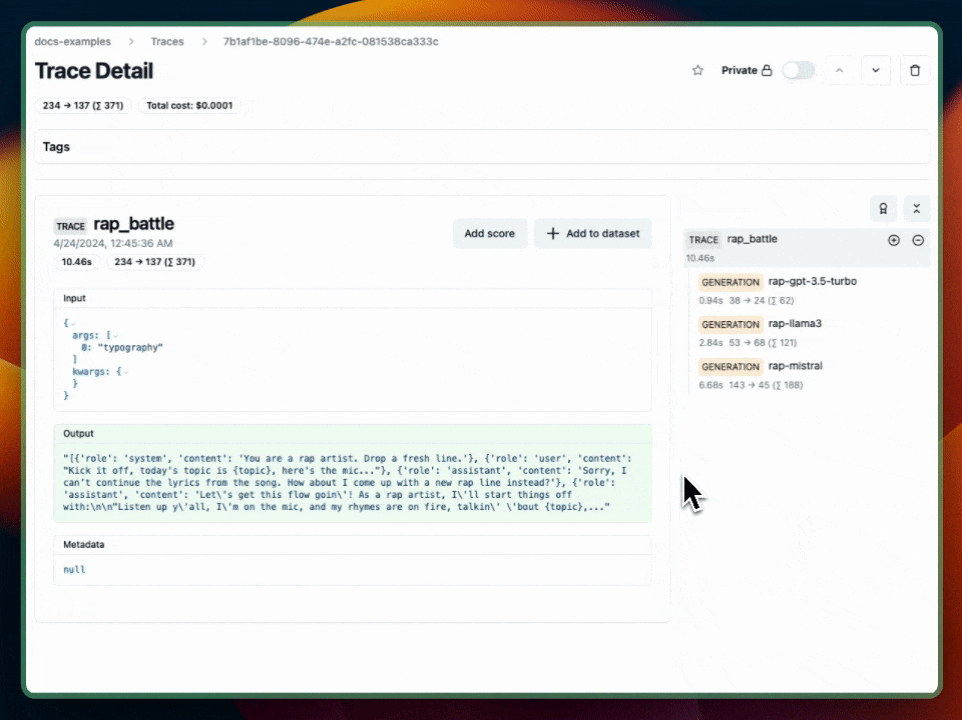
Learn more
Check out the docs to learn more about all components of this stack:
- LiteLLM Proxy (opens in a new tab)
- Langfuse OpenAI SDK Wrapper (opens in a new tab)
- Langfuse (opens in a new tab)
If you do not want to capture traces via the OpenAI SDK Wrapper, you can also directly log requests from the LiteLLM Proxy to Langfuse. For more details, refer to the LiteLLM Docs (opens in a new tab).