Instructor Integration
Instructor (opens in a new tab) (GitHub (opens in a new tab)) is a popular library to get structured LLM outputs.
Instructor makes it easy to reliably get structured data like JSON from Large Language Models (LLMs) like GPT-3.5, GPT-4, GPT-4-Vision, including open source models like Mistral/Mixtral from Together, Anyscale, Ollama, and llama-cpp-python. By leveraging various modes like Function Calling, Tool Calling and even constrained sampling modes like JSON mode, JSON Schema; Instructor stands out for its simplicity, transparency, and user-centric design. Under the hood, Instructor leverages Pydantic to do the heavy lifting, and provides a simple, easy-to-use API on top of it by helping you manage validation context, retries with Tenacity, and streaming Lists and Partial responses.
This is a cookbook with examples of the Langfuse Integration for Python.
Setup
%pip install langfuse openai pydantic instructor --upgradeInitialize the Langfuse client with your API keys from the project settings in the Langfuse UI and add them to your environment.
import os
# get keys for your project from https://cloud.langfuse.com
os.environ["LANGFUSE_PUBLIC_KEY"] = ""
os.environ["LANGFUSE_SECRET_KEY"] = ""
# your openai key
os.environ["OPENAI_API_KEY"] = ""Get started
It is easy to use instructor with Langfuse. We use the Langfuse OpenAI intgeration (opens in a new tab) and simply patch the client with instructor. This works with both synchronous and asynchronous clients.
Langfuse-Instructor integration with sychnronous OpenAI client
import instructor
from langfuse.openai import OpenAI
from pydantic import BaseModel
# Patch Langfuse wrapper of synchronous OpenAI client with instructor
client = instructor.patch(OpenAI())
class WeatherDetail(BaseModel):
city: str
temperature: int
# Run synchronous OpenAI client
weather_info = client.chat.completions.create(
model="gpt-3.5-turbo",
response_model=WeatherDetail,
messages=[
{"role": "user", "content": "The weather in Paris is 18 degrees Celsius."},
],
)
print(weather_info.model_dump_json(indent=2))
"""
{
"city": "Paris",
"temperature": 18
}
"""Langfuse-Instructor integration with asychnronous OpenAI client
import instructor
from langfuse.openai import AsyncOpenAI
from pydantic import BaseModel
# Patch Langfuse wrapper of synchronous OpenAI client with instructor
client = instructor.apatch(AsyncOpenAI())
class WeatherDetail(BaseModel):
city: str
temperature: int
# Run asynchronous OpenAI client
task = client.chat.completions.create(
model="gpt-3.5-turbo",
response_model=WeatherDetail,
messages=[
{"role": "user", "content": "The weather in Paris is 18 degrees Celsius."},
],
)
response = await task
print(response.model_dump_json(indent=2))
"""
{
"city": "Paris",
"temperature": 18
}
"""Example
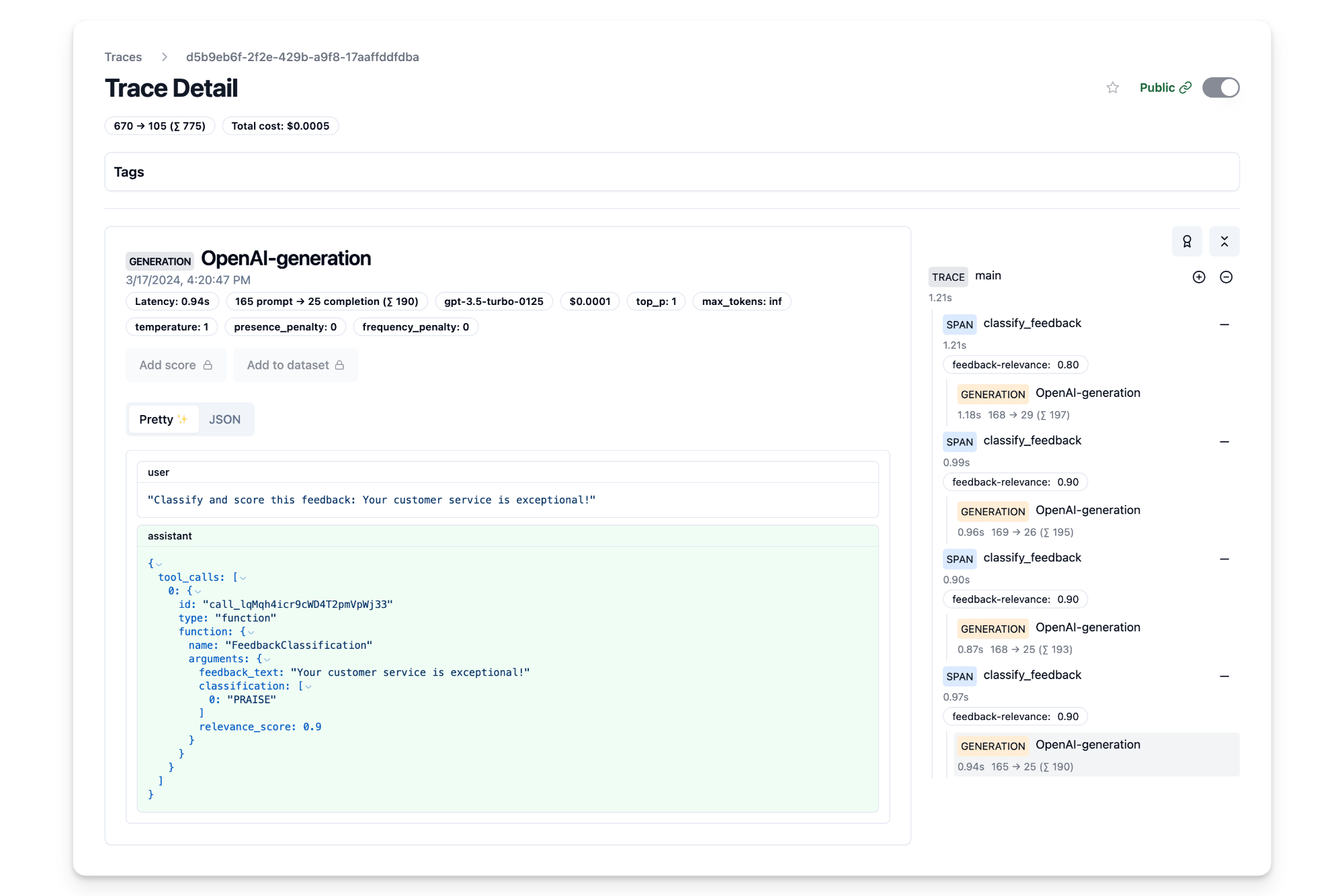
In this example, we first classify customer feedback into categories like PRAISE, SUGGESTION, BUG and QUESTION, and further scores the relvance of each feedback to the business on a scale of 0.0 to 1.0. In this case, we use the asynchronous OpenAI client AsyncOpenAI to classify and evaluate the feedback.
from typing import List, Tuple
from enum import Enum
import asyncio
import instructor
from langfuse import Langfuse
from langfuse.openai import AsyncOpenAI
from langfuse.decorators import langfuse_context, observe
from pydantic import BaseModel, Field, field_validator
# Initialize Langfuse wrapper of AsyncOpenAI client
client = AsyncOpenAI()
# Patch the client with Instructor
client = instructor.patch(client, mode=instructor.Mode.TOOLS)
# Initialize Langfuse (needed for scoring)
langfuse = Langfuse()
# Rate limit the number of requests
sem = asyncio.Semaphore(5)
# Define feedback categories
class FeedbackType(Enum):
PRAISE = "PRAISE"
SUGGESTION = "SUGGESTION"
BUG = "BUG"
QUESTION = "QUESTION"
# Model for feedback classification
class FeedbackClassification(BaseModel):
feedback_text: str = Field(...)
classification: List[FeedbackType] = Field(description="Predicted categories for the feedback")
relevance_score: float = Field(
default=0.0,
description="Score of the query evaluating its relevance to the business between 0.0 and 1.0"
)
# Make sure feedback type is list
@field_validator("classification", mode="before")
def validate_classification(cls, v):
if not isinstance(v, list):
v = [v]
return v
@observe() # Langfuse decorator to automatically log spans to Langfuse
async def classify_feedback(feedback: str) -> Tuple[FeedbackClassification, float]:
"""
Classify customer feedback into categories and evaluate relevance.
"""
async with sem: # simple rate limiting
response = await client.chat.completions.create(
model="gpt-3.5-turbo",
response_model=FeedbackClassification,
max_retries=2,
messages=[
{
"role": "user",
"content": f"Classify and score this feedback: {feedback}",
},
],
)
# Retrieve observation_id of current span
observation_id = langfuse_context.get_current_observation_id()
return feedback, response, observation_id
def score_relevance(trace_id: str, observation_id: str, relevance_score: float):
"""
Score the relevance of a feedback query in Langfuse given the observation_id.
"""
langfuse.score(
trace_id=trace_id,
observation_id=observation_id,
name="feedback-relevance",
value=relevance_score
)
@observe() # Langfuse decorator to automatically log trace to Langfuse
async def main(feedbacks: List[str]):
tasks = [classify_feedback(feedback) for feedback in feedbacks]
results = []
for task in asyncio.as_completed(tasks):
feedback, classification, observation_id = await task
result = {
"feedback": feedback,
"classification": [c.value for c in classification.classification],
"relevance_score": classification.relevance_score,
}
results.append(result)
# Retrieve trace_id of current trace
trace_id = langfuse_context.get_current_trace_id()
# Score the relevance of the feedback in Langfuse
score_relevance(trace_id, observation_id, classification.relevance_score)
# Flush observations to Langfuse
langfuse_context.flush()
return results
feedback_messages = [
"The chat bot on your website does not work.",
"Your customer service is exceptional!",
"Could you add more features to your app?",
"I have a question about my recent order.",
]
feedback_classifications = await main(feedback_messages)
for classification in feedback_classifications:
print(f"Feedback: {classification['feedback']}")
print(f"Classification: {classification['classification']}")
print(f"Relevance Score: {classification['relevance_score']}")
"""
Feedback: I have a question about my recent order.
Classification: ['QUESTION']
Relevance Score: 0.0
Feedback: Could you add more features to your app?
Classification: ['SUGGESTION']
Relevance Score: 0.0
Feedback: The chat bot on your website does not work.
Classification: ['BUG']
Relevance Score: 0.9
Feedback: Your customer service is exceptional!
Classification: ['PRAISE']
Relevance Score: 0.9
"""