🚅 LiteLLM Integration
LiteLLM (GitHub (opens in a new tab)): Use any LLM as a drop in replacement for GPT. Use Azure, OpenAI, Cohere, Anthropic, Ollama, VLLM, Sagemaker, HuggingFace, Replicate (100+ LLMs).
There are three ways to integrate LiteLLM with Langfuse:
- LiteLLM Proxy with OpenAI SDK Wrapper, the proxy standardizes 100+ models on the OpenAI API schema and the Langfuse OpenAI SDK wrapper instruments the LLM calls.
- LiteLLM Proxy which can send logs to Langfuse if enabled in the UI.
- LiteLLM Python SDK which can send logs to Langfuse if the environment variables are set.
Example trace in Langfuse using multiple models via LiteLLM:
1. LiteLLM Proxy + Langfuse OpenAI SDK Wrapper
This is the preferred way to integrate LiteLLM with Langfuse. The Langfuse OpenAI SDK wrapper automatically captures token counts, latencies, streaming response times (time to first token), API errors, and more.
How this works:
- The LiteLLM Proxy (opens in a new tab) standardizes 100+ models on the OpenAI API schema
- and the Langfuse OpenAI SDK wrapper (Python, JS/TS) instruments the LLM calls.
To see a full end-to-end example, check out the LiteLLM cookbook.
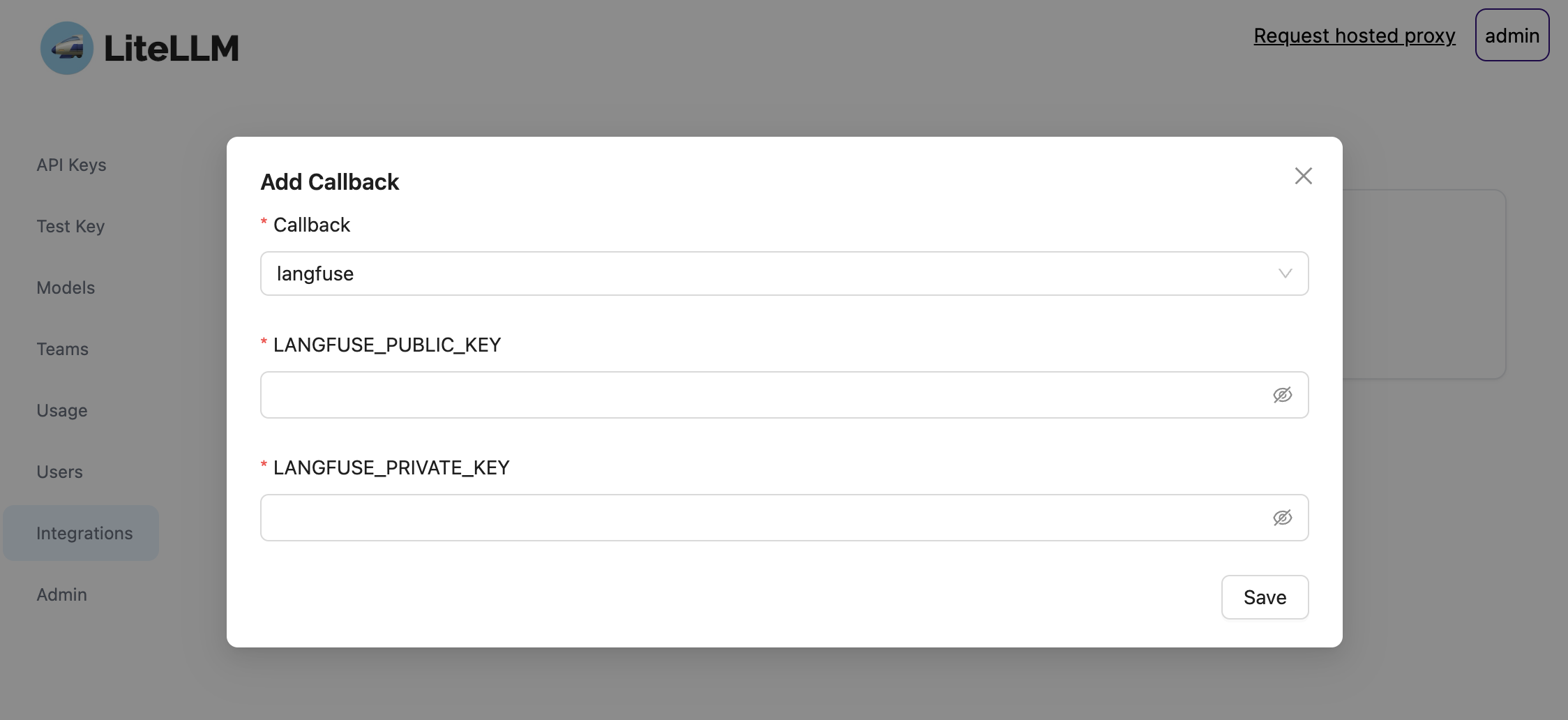
2. Send Logs from LiteLLM Proxy to Langfuse
By setting the callback to Langfuse in the LiteLLM UI you can instantly log your responses across all providers. For more information on how to setup the Proxy UI, see the LiteLLM docs (opens in a new tab).
3. LiteLLM Python SDK
Instead of the proxy, you can also use the native LiteLLM Python client. You can find more in-depth documentation in the LiteLLM docs (opens in a new tab).
pip install langfuse>=2.0.0 litellmfrom litellm import completion
## set env variables
os.environ["LANGFUSE_PUBLIC_KEY"] = ""
os.environ["LANGFUSE_SECRET_KEY"] = ""
# Langfuse host
os.environ["LANGFUSE_HOST"]="https://cloud.langfuse.com" # 🇪🇺 EU region
# os.environ["LANGFUSE_HOST"]="https://us.cloud.langfuse.com" # 🇺🇸 US region
os.environ["OPENAI_API_KEY"] = ""
os.environ["COHERE_API_KEY"] = ""
# set callbacks
litellm.success_callback = ["langfuse"]
litellm.failure_callback = ["langfuse"]
Quick Example
import litellm
# openai call
openai_response = litellm.completion(
model="gpt-3.5-turbo",
messages=[
{"role": "user", "content": "Hi 👋 - i'm openai"}
]
)
print(openai_response)
# cohere call
cohere_response = litellm.completion(
model="command-nightly",
messages=[
{"role": "user", "content": "Hi 👋 - i'm cohere"}
]
)
print(cohere_response)
Use within decorated function
If you want to use the LiteLLM SDK within a decorated function (observe() decorator), you can use the langfuse_context.get_current_trace_id() method to get the current trace ID and pass it to the LiteLLM SDK.
from litellm import completion
from langfuse.decorators import langfuse_context, observe
@observe()
def fn():
# set custom langfuse trace params and generation params
response = completion(
model="gpt-3.5-turbo",
messages=[
{"role": "user", "content": "Hi 👋 - i'm openai"}
],
metadata={
"trace_id": langfuse_context.get_current_trace_id(), # set langfuse trace ID
},
)
print(response)GitHub issue (opens in a new tab) tracking a native integration that will automatically capture nested traces when the LiteLLM SDK is used within a decorated function.
Set Custom Trace ID, Trace User ID and Tags
from litellm import completion
# set custom langfuse trace params and generation params
response = completion(
model="gpt-3.5-turbo",
messages=[
{"role": "user", "content": "Hi 👋 - i'm openai"}
],
metadata={
"generation_name": "test-generation", # set langfuse Generation Name
"generation_id": "gen-id", # set langfuse Generation ID
"trace_id": "trace-id", # set langfuse Trace ID
"trace_user_id": "user-id", # set langfuse Trace User ID
"session_id": "session-id", # set langfuse Session ID
"tags": ["tag1", "tag2"] # set langfuse Tags
},
)
print(response)
Use LangChain ChatLiteLLM + Langfuse
pip install langchainfrom langchain.chat_models import ChatLiteLLM
from langchain.schema import HumanMessage
import litellm
chat = ChatLiteLLM(
model="gpt-3.5-turbo"
model_kwargs={
"metadata": {
"trace_user_id": "user-id", # set Langfuse Trace User ID
"session_id": "session-id", # set Langfuse Session ID
"tags": ["tag1", "tag2"] # set Langfuse Tags
}
}
)
messages = [
HumanMessage(
content="what model are you"
)
]
chat(messages)
Customize Langfuse Python SDK via Environment Variables
To customise Langfuse settings, use the Langfuse environment variables. These will be picked up by the LiteLLM SDK on initialization as it uses the Langfuse Python SDK under the hood.
Learn more about LiteLLM
What is LiteLLM?
LiteLLM (opens in a new tab) is an open source proxy server to manage auth, loadbalancing, and spend tracking across more than 100 LLMs. LiteLLM has grown to be a popular utility for developers working with LLMs and is universally thought to be a useful abstraction.
Is LiteLLM an Open Source project?
Yes, LiteLLM is open source. The majority of its code is permissively MIT-licesned. You can find the open source LiteLLM repository on GitHub (opens in a new tab).
Can I use LiteLLM with Ollama and local models?
Yes, you can use LiteLLM with Ollama and other local models. LiteLLM supports all models from Ollama, and it provides a Docker image for an OpenAI API-compatible server for local LLMs like llama2, mistral, and codellama.
How does LiteLLM simplify API calls across multiple LLM providers?
LiteLLM provides a unified interface for calling models such as OpenAI, Anthrophic, Cohere, Ollama and others. This means you can call any supported model using a consistent method, such as completion(model, messages), and expect a uniform response format. The library does away with the need for if/else statements or provider-specific code, making it easier to manage and debug LLM interactions in your application.